

引 言

随着大数据技术的不断发展,银行业对海量数据的查询、分析、预测、数据挖掘等业务场景日益增多。针对此类场景,业界普遍使用两种数据技术进行海量数据的处理:一种是基于MPP(Massively Parallel Processing)的海量数据处理框架技术;另一种是基于Hadoop并行计算框架的分布式数据处理技术。由于两种体系的数据存储与数据处理原理不同,异构数据融合已成为行业面临的普遍问题,打通新型Hadoop体系数据湖和传统MPP数据仓库之间的技术壁垒成为金融业特别是银行业面临的主要需求。
本文以光大银行多源数据查询平台为例,介绍了一种大数据交互式查询和异构数据源联合查询的方式,并结合光大银行大数据查询场景,实现定制化开发,有效提升数据分析人员的使用幸福感,降低不同数据源的搬家成本。
现有问题分析
光大银行存在“基于MPP框架的GaussDB数据仓库”和“基于Hadoop框架的数据湖”两种体系。其中,Hadoop体系的数据主要通过Hue进行查询。作为Hadoop体系的Web工具,Hue支持浏览器端的 Web 控制台上与 Hadoop 集群的交互,如操作 HDFS 上的数据、运行 MapReduce Job、执行 Hive 的 SQL 语句和浏览 Hbase 数据库等,其对Hadoop大数据的查询主要通过Hive和Impala引擎,其提供的前端查询页面如图1所示。
图1 Hue前端查询页面
由于Hive与Impala两种不同的引擎查询原理各不相同,带来了以下三个问题:
1. Hive引擎查询时间长。Hive采用类SQL语句开发,它的查询模式可以理解为一个SQL语句的查询,会转化成多个MapReduce任务,一个接一个地执行,执行中间结果通过对磁盘的读写来同步。这种查询模式,每次执行都需要从磁盘读取数据,并且在计算完成后需要将中间结果写入磁盘中,I/O开销很大,多个MapReduce任务之间的衔接也由于涉及I/O开销,会产生较高延迟。这造成了通过Hive引擎查询,查询结果往往需要5-10分钟甚至更久的查询时长的情况。
2. Impala引擎跨平台能力存在挑战。Impala引擎查询没有选用MapReduce的传统方式,而是直接从HDFS拉取源数据内容到内存中进行计算。虽然避免了磁盘I/O开销,但是光大银行采用的Impala混部的方式容易导致Impala查询性能不稳定。且不同于Java语言能够直接通过虚拟机(JVM)实现跨平台运行,Impala采用C++语言编写,从这一点来看,在Impala引擎与x86、ARM等多种CPU芯片适配时,会不可避免地增加不同操作系统间移植的难度。
3. 无法实现跨数据源的联合查询。Hive与Impala引擎都与Hadoop生态联系密切,只能通过Hive SQL对Hadoop的数据文件进行查询,无法实现不同数据库之间的联合查询。
基于openLooKeng的
多源数据查询平台整体介绍
为解决上述问题,业界普遍选用Presto、Trino、openLooKeng几种不同的查询引擎,这三种引擎都基于Java语言开发,支持交互式查询场景与异构数据源联合查询场景。这三种引擎的本质相同,但由不同的社区维护:Presto由原Facebook(现meta)维护,Trino从Presto独立出来由开发创始人维护,openLooKeng由国内华为主导维护。
考虑开源引擎开发时与社区交流的便捷性,光大银行引入了openLooKeng引擎,根据自身业务特色实现定制化开发,建设了多源数据查询平台,实现对Hadoop体系数据Ad-hoc查询场景和不同数据源之间的联合查询场景。
1.openLooKeng查询原理
openLooKeng组件存在两个服务进程,管理节点进程与工作节点进程。当客户端发起一条查询SQL后,SQL会被发送到管理节点上,管理节点完成SQL解析等一系列工作,将SQL划分为多个task,并将task分发至工作节点,由工作节点将数据源的数据拉取到工作节点内存中,并行完成每个task的计算结果,最终汇总出一个最终计算结果返回至管理节点上,由管理节点返回至客户端。查询原理如图2所示。
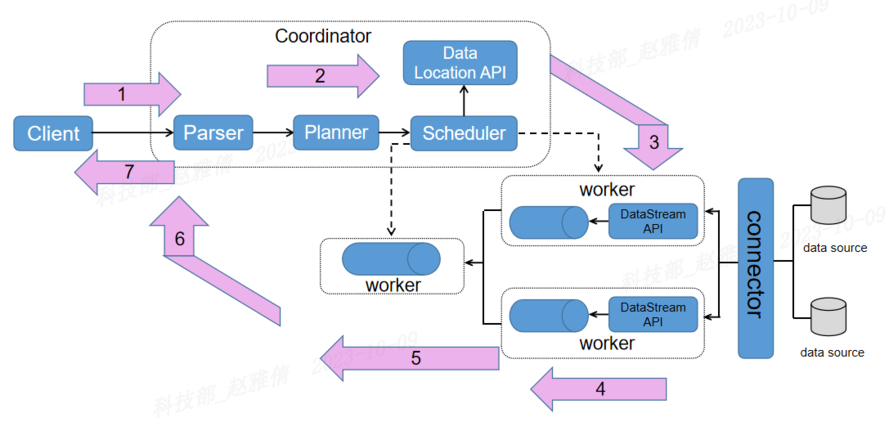
图2 openLooKeng查询原理
2.多源数据查询平台整体介绍
多源数据查询平台引入openLooKeng开源组件,实现对Hive、Hbase、Kudu、Kafka、GaussDB、Mysql等多个数据源的查询,同时能够对查询各类数据源时出现的问题进行功能修改,并基于业务场景,单独部署两个物理集群,将Ad-hoc查询场景与JDBC系统联机查询场景物理隔离。具体系统功能模块如图3所示。
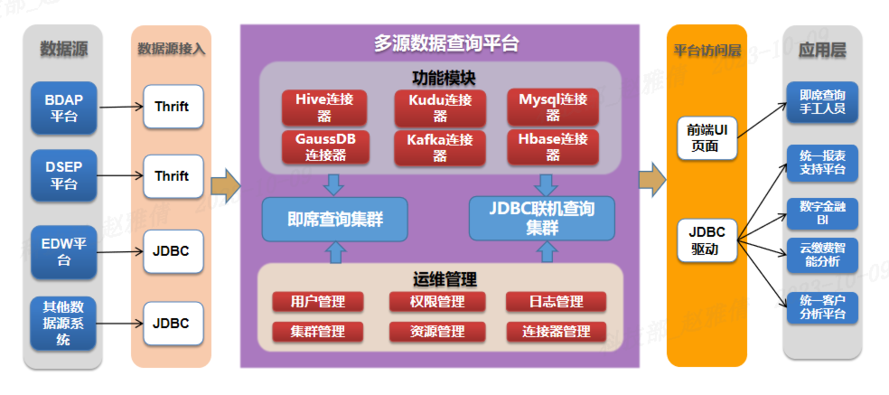
图3 系统逻辑架构
3.多源数据查询平台技术亮点
目前,平台已经具备以下六项技术能力:
一是实现多源数据查询平台对Hadoop数据体系与GaussDB数据库的联合查询,解决跨源数据导入问题,实现数据快速查询。
二是提供JDBC接口查询服务。平台定制开发使用HTTP协议模式的密码鉴权安全认证方式,无需证书,替换原有的HTTPS协议需要证书的配置方式,降低配置和使用复杂性,使各个业务系统可以更加便捷地通过报表工具通过本平台实现报表查询。
三是新增数据源。平台定制开发Kudu数据库查询功能,使接入平台的各类应用能够对Kudu数据库进行报表查询,以及实现Kudu与其他数据源关联的报表查询服务。
四是高可用部署。区别于业内使用软件部署方式,平台结合光大银行业务特色,基于管理节点与工作节点状态监听功能,再利用F5硬件设备实现管理节点的高可用,使双管理节点同时提供服务,提高业务查询稳定性。
五是实现平台运维管理。平台定制开发了用户管理和审计日志管理功能,支持各个管理节点同时存储用户行为日志信息(包括用户SQL发生时间、处理时长等),有效提升运维管理效能。
六是实现平台运营分析功能。平台定制开发了使用本平台查询的在线人数统计、不同业务系统查询量等运营指标分析功能,有效提升平台管理者的运营分析决策能力。
多源数据查询平台应用场景
多源数据查询平台作为光大银行基础性查询平台,为全行各个领域数据分析人员提供数据查询通道,以秒级数据查询响应能力服务全行云缴费、零售客户、数字金融、智能营销各个业务领域。平台可应用于以下两种查询场景。
1.Ad-hoc即席查询场景。平台提供前端页面,实现对多种数据源的灵活查询,Ad-hoc即席查询即用户快速地执行自定义SQL(可能无法提前运算和预测)。平台使用三层架构模型(catalog.schema.table)唯一确定一张表,其中catalog对应数据源的概念,每一个catalog可以简单理解为某一个数据源的实例,schema理解为database,以此方式可实现不同数据源之间的联合查询。前端查询如图4多源数据查询平台前端页面图所示。
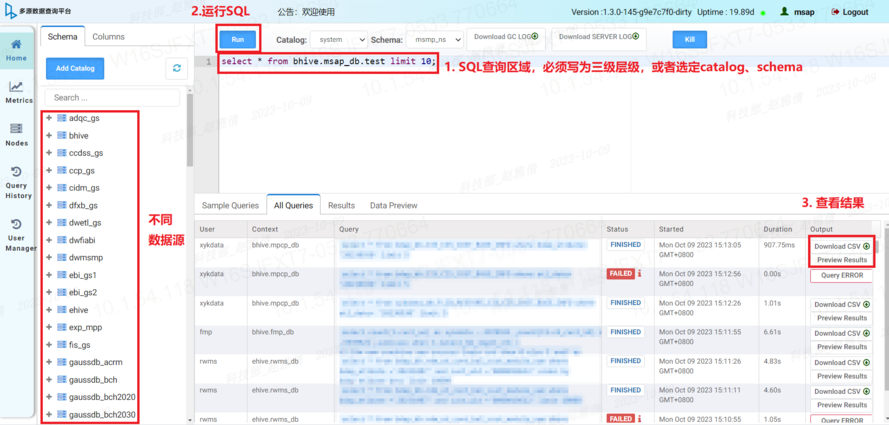
图4 多源数据查询平台前端页面
2.JDBC服务查询场景。平台提供JDBC接口给各个下游业务系统,实现业务系统对Hadoop数据、GaussDB数据的联机查询。平台使用的openLooKeng引擎基于内存对不同数据源进行数据查询,其提供的JDBC接口用于对接入平台上的各个数据源进行查询处理。通过平台的一个JDBC接口,可实现底层多个数据源的查询分析与处理。
未来展望
目前,openLooKeng组件已经覆盖了光大银行内部所有主流数据源。后续,平台将持续提升自主可控能力,推进现有openLooKeng组件与新技术组件的融合(例如Hudi,支持实时数据湖场景数据探查)。